This week I made progress on 2 of the installations, and made some supporting images for the exhibition itself.
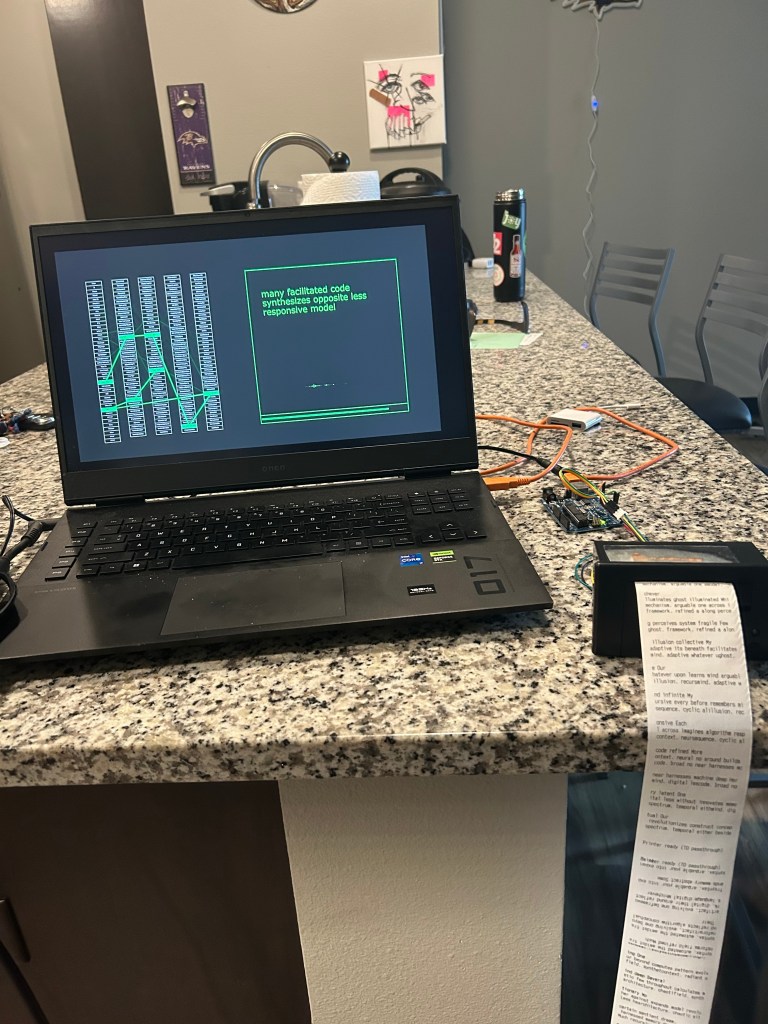
The first installation I made a lot of progress on was Non-Sentences, in which I got the thermal receipt printer all hooked up and talking with TouchDesigner, so that every sentence it generates pings to the Arduino so it gets printed. This took a little bit of head banging within TouchDesigner and with the Arduino IDE, but eventually I got it to work. The main thing was the right chip settings, which is obvious in hindsight but with the chip Alex giving me to borrow a Diecimila instead of an Uno which I was more familiar with, just a couple changing of settings was good to get it talking to TD and to get the sentences put out on the printer. The good thing was that within TouchDesigner I already had a module that spit out the full sentence in one go, which was left over from before I had the console type-out effect of each character appearing one by one. Having a little script that communicated with a Serial DAT in TD lets it talk to the printer, and with a slight modification of the print layout for installation purposes, it was good to go.
I think the printer adds a lot. As I said in a previous post it adds a more tangent physical aspect to the digital words that are output by this LLM, and with the huge line that I already managed to print that reached my floor from my apartments counter, I can see the vision of it piling up a lot more over time. As far as the words on the paper itself, in the instance I was running it the sentences were backing up on themselves a little bit, with words and characters being a little re-arranged in just a bit more of a non-sense random way. I think this can unintentionally add a bit to the "Non-Sense" idea of the record keeping of these AI outputs, where the sense it makes becomes even more diluted, with even smaller strings of a couple words making sense. Overtime this adds up to this wall of text with no meaning besides what we make, akin to a never-ending chat with an LLM that can keep going forever and ever, losing that meaning over time. Visually, this also connects to the image/latent space ideas I brought up earlier this semester. A comparable visual is the "library of babel", which is a thought experiment / actual website comprised of theoretically every piece of text that can ever and will ever be written. Of course, most of it is nonsense characters in chapters of books of meaningless-ness, but technically everything is in there, from the cure to cancer to the exact details of the day you die, to my entire written portion of my thesis, already written for me. Think infinite monkey's on infinite typewriters across all of time and space. In a way, "Non-Sentences" is a physical slice of the library, one that I am really satisfied with how it has progressed.
Secondly is the "How Original?" project, which again involves pose tracking to match a historical photo with a persons pose from a live feed. For class this week I was really focused on getting a good image database of historical poses to feed into the media pipe pose detection scripts in TouchDesigner. This was much easier said than done, with lots of ups and downs in finding good sources of images, navigating online databases, and downloading the images to my database file. The good thing is that the backend system for this is mostly working, so I have would only need to plug in my images into the system and re-run it to see how accurate I can get it to a persons pose. As far as the images, again I was looking at all different databases with Creative Commons licenses, from the Library of Congress, Internet Archive, New York Times archive, British Library, and Stanfords image archive. I found a lot of good images on there, but in the end I found I might have been overthinking it a little bit, and found that simply looking on Google Images or Pinterest was better than combing through these archives, because I could find more useable images faster and in higher quality/quantity.
In the process of downloading these images I was thinking that in essence I was acting like an AI model, sourcing images all across the internet with or without permission to create this experience. As the experience connects us with our collective past and the inability to separate ourselves from it, the process is a connection with it as well, and a connection to how an AI model sources these images, but from a distinctly human angle. When I see an image of 1920's child laborers having fun, I get an emotional reaction, but I'm also analyzing it for their poses and how viable it would be for the pose detection system and if it a person interacting with the installation would strike that pose. All that to say, on the topic of AI literacy, the connective tissue of our past as and future of a species are closely intertwined, with many gray areas. These real people from the past aren't consenting to having their images or likeness used by the models or the training sets of encoding "vintage" aesthetic vibes, just as they aren't consenting to have their images stored forever in a Creative Commons database for the entire world to see. In a way they will live forever through these methods, and through this installation, but in a more socially acceptable way than if you encode grandmas likeness to be deepfaked so you can talk to her after she's passed. Begging questions of how these past connections strengthen or weaken our present connections with technology, and how we can learn to make these connections more responsible for the future.
At the time of writing I've finished gathering 300 distinct images for the project. I'll include some samples below, but my plans for this break are to plug them into the system to see how similar I can get them to my poses (originally achieving 0.2 or less similarity with the previous ML database), and to begin more in-depth the brainwave project. I have it talking to TD through OSC data, it's just a matter of laying it out and fine tuning some of the finicky nature of the actual reading of a persons brainwaves into a more smooth experience.
Once I've made progress on that, I will need to fine tune the rest of the installation pieces, and work on moving them from computer to computer, as there can be some complications that come with this, ultimately to end the semester with a clear designation of which of my computers (beefy Nvidia laptop, my 2 Macs, or the mini-windows one's Alex is letting me borrow) will host which projects for the gallery.
What I’ve Read
This week I was able to read a little more of "Transcending Imagination", and Chapter 9 had some interesting things about the myth of the "creative genius"
Manu dives into the belief that creativity is an innate gift possessed only by a select few “geniuses.” He argues that this myth, which emerged during the Romantic era and is reinforced through figures like Mozart, Leonardo Da Vinci, and Einstein, misrepresents the true nature of creativity as a collective and iterative process. He goes through several misconceptions: that talent is purely innate, that creativity arises from sudden “Eureka” moments, that geniuses create in isolation, that creativity is chaotic rather than structured, and that madness is a necessary companion to creative brilliance. Manu reframes creativity as a skill honed through dedication, discipline, collaboration, and resilience, rather than divine inspiration or individual genius.
The second half of the chapter expands this critique on "the creative genius" in light of AI and generative technologies. Manu suggests that tools like AI reveal creativity to be a social process rather than an individual miracle, as algorithms themselves build upon collective human data and knowledge. Rather than threatening creativity, AI democratizes it, lowering barriers for participation and encouraging collaboration across backgrounds and disciplines. By enabling more people to create and contribute, AI disperses the myth of the solitary genius and replaces it with a model of collaborative intelligence, where innovation emerges from networks of humans and machines working together. I think this makes sense given the current creative climate with social media and AI. Over the years there have been less and less of these creative geniuses popping up. You don't see someone captivating the world like a Michael Jackson anymore, the closest maybe being Taylor Swift or Kanye, and even then they have decades long careers at this point. I think the combination of social media and AI in a way allows for a sort of individualized natural selection of what people deem creative, where novelty and value can be mapped to views and likes, although there are certainly ways to game the system, the merit of something creative and captivating is allowed to at the same time be made an easier process, and to reach all around the world much quicker. In this way the "creative genius" of our time can be anyone, but remains a human thing. AI slop posts typically don't get much traction apart from the "boom" of a new model coming out, or hate from a select viewpoint. One of the practitioners I interviewed has said he's gotten next to no hate for using AI in his works, and he postulated it was because of the uniqueness and meaning behind the work that allowed for this, making his work break the typical AI visual language and the commentary that follows it.
Where the Next Steps are Leading
As I said previously, over the break I'll primarily work on the "How Original" pose tracking project for maybe 1/4 of my time, and the rest focused on pushing forward with the brainwave scanner, with the ultimate goal of finalizing the installations for the end of the semester, to work on planning the workshop and written portion of the interviews for winter break.
This week I made a lot of good progress in a bunch of the different installation projects, and made moves to getting a space to have them actually installed in Gallery 181 in the design building next to Carly's work, in that I actually have the gallery space reserved! I added a great deal of interactivity to the Emergent Garden, and made solid work on two somewhat smaller works that I think could be included as an interactive and introspective experience with AI, working titles being "How Original?" and "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made" (a bit pretentious of a title but I'll add more context to what that actually means and entails below).
Emergent Garden
Like I said I added much more interactivity to the Emergent Garden, combining aspects of the drawing tool I made a while back with a gesture system that allows the user to draw shapes that are then interpreted to different flowers. The main "brush" is a simple circle with a feedback that keeps the previous frames visible, and is situated in the midpoint between a users index finger and thumb. By moving their hand around they can draw shapes on the canvas, and by pinching their fingers together or apart, they can change the size of the brush. To change the color, the user gives a thumbs up to the camera, which cycles the color of the brush from red, purple, blue, green, orange, and white. Finally, the user can clear the entire canvas by pointing their finger up, so that they don't have to worry about erasing every single shape they've made. I added pictogram instructions that will be fixed on screen over the camera feed, and the shapes they draw are made slightly transparent so they can still see their hands and themselves as they draw.
Right now the motion tracking takes into account only one hand, but soon I'd like to add the ability for more than one hand to be tracked to add a more collaborative aspect of interaction. Another issue I have with it right now is that the camera feed is at a 16:9 resolution, while the AI is only capable of outputting a 1:1 square resolution. This means that the actual size of the drawing canvas, or camera feed, is currently hidden behind the AI canvas. It's not much of a usability issue, but this means that some of the drawing could be under the AI canvas, and make shapes that don't correspond to what a user is actually seeing. This is somewhat subverted by the catch all erase function, but it is an area of improvement I'd like to make. More so, this limits the potential of shape exploration by the user, with a wider canvas allowing for more variation over time and over users. That said, it is less of a priority than the collaborative functionalities I'd like to make. I also have begun setting up systems for the changing of the AI prompts, but I'm still undecided if I want a midi pad to control it, or if I want some other options such as having them cycle slowly through time between flowers, insects, and fauna, with the Emergent [title] changing to let a user know what their shapes are currently being interpreted to, and to make the small lines of code that are added in post over the AI canvas to be dynamic and changing, to maybe further emphasize the collaboration between the user and the system. Now that I have the gallery space too I can start thinking more about presentation options. Right now the two feeds are juxtaposed, which I think works well, but I can think about other options than having a TV monitor in the space, such as if I want the AI output to be projected onto the wall next to some posters I make, or if the entire feed is projected. Something to think about, and the projection can be incorporated with another new project I've made good progress on.
How Original?
This is a new project that stems from AI image databases. The structure of the database involves billions of images scraped from the internet (often without permission) to be used in training. In order for an image generator to be able to generate any given prompt, these images cover all sorts of ground from art to photography, from nature and industry, to animals and people. From all this coverage there is one thing that unites all of the images in the database, and that is the human behind them all. Even a picture of a tree deep in the amazon rain forest, or of a galaxy billions of light years away, the underlying factor that makes the image possible to be viewed and interpreted in the first place is the human ingenuity, from the person who took the picture, or from the years of collaboration and accumulated knowledge that allowed for the creation of the image-creating devices. This is true of AI as well, as the technology behind processes has taken years of hard human work to achieve, and the training images even more: spanning from the present day to the beginning of documented history.
The nature of the images collected and repurposed has left some to be perturbed by the process, and maybe rightfully so, since no permissions are often given for an image to be fed to the model. However, the taking from one source and repurposing for something new, is in fact not new. From renaissance ideas of antiquity and humanism inspired from ancient Greek philosophy, or the architecture of U.S. government buildings directly inspired from ancient roman architecture, our inventions and our technology are seldom, if ever, actually invented more so as they borrow ideas from the past. Insert Virgil Abloh's 3% rule: To make something culturally significant, you only need to modify 3% of something that already exists. Machines and AI have a unique way of interpreting the preexisting images and data fed into it, "remembering" the past differently than we do. In the instance of gesture and body tracking, a machine with inputs of millions of human bodies and gestures across history, is much better at measuring the distances between points and vectors, than it is at actually understanding historical significance or emotion. This is not necessarily a flaw, but more of a confrontation of the limits of AI and machine logic, and the irreducible complexity of human expression.
This preamble leads to the "How Original?" project. The idea is to match a live gesture from a viewer or user, with that of a historical image of a person doing a near similar gesture to that of the viewer. In this instance, AI, often framed as a tool of the future, is repurposed as a medium for engaging with our collective past. (An interaction with time, and a focus of the 3rd project discussed in this post).
Currently, the database being used in the pictures is from open source training sets used in machine vision, and don't really match quite well with the users live gestures. The current database was used more as a means to get the backend logic working, with the mapping of joints on a picture and somewhat matching that to the live stream. The good thing here is that the hard work of actually coding is mostly complete, what's left for me to do is gathering a database of open source historical photos (I'm targeting anything pre-1960 so that the time between the "now" and the "then" is more drastic). The bad thing is that this will likely be tedious and manual, having to find pictures that are of a decent resolution, and show a persons full body, and I'll have to gather enough to get a full mapping of a person's possible gestures. I'm not targeting complete similarity between poses, I think around .7 would do the trick in getting the idea across. The idea of viewing history as a living collage and peeling back layers of time, where our technologies and our gestures are both individual and collective, and repetitions of ideas are not coincidence or con-work, but a continuity of humanity and our stubborn refusal to let go of the past. The idea of working with AI through time is a strong basis for the last project I've put a little work on: "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made".
The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made
Spoiler alert: it's not "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made". However, if you tell an AI image model to create "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made", it will generate an image "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made". But as you would guess, what it would generate would more likely be "The Single Greatest Piece of Meh Confined to a Square Canvas".
Similarly, AI as a technology is often heralded in the hype cycle as this technology that will change everyone's lives for the better, make work easier, but has it actually? Or has it just increased CEO's profit margins and make funny slop memes on TikTok? In the hate cycle, people say AI will take the common-folks jobs, ruin the environment, or that the bubble will burst soon and the stock market will fall, a depression will commence, soon followed by the end of the world. But how much is AI impacting the environment compared to things like the oil leaked from massive shipping vessels or the already existing data centers that house the servers for things like Google and Instagram that people don't seem to have as much of a problem with? Will the bubble actually burst or will the progress of AI just lead to massive expansion? A common endpoint for both sides is the idea of a singularity that looms over our heads that in either case would cause massive upheaval of everyone's lives, maybe not good, maybe not bad, but certainly massive change. These areas of unknown and uncertainty can only be known after time allows it.
Time is a funny thing when it comes to AI. As in the previous section, AI connects us to our collective past and our potential future. In the case of image or video generation, AI generates near-instantly what could take a traditional artist weeks or months. What if we subverted this time-to-generate, lengthening the time it takes to generate from almost instantaneous, to hours, or weeks, or years, or even centuries?
Using time as this supplementary medium is not entirely new as a concept (repetition through time again). The pitch drop experiment is the worlds longest running "experiment" that sees pitch (a highly viscous liquid comparable to tar) being dropped through a beaker. Because of how viscous it is, the time between singular drops lasts anywhere between 8-14 years. This has sensationalized it in a way, with a constant live-stream of the beaker being filled up with viewers whenever a drop is about to...drop. With how much liquid is in it given how infrequently it drops, the beaker is expected to continue dripping for at least a hundred more years until it runs out, with only 9 drops so far. On the more artistic side, a John Malkovich movie called 100 years, will fittingly come out in 2115, 100 years after it was made and likely after the entirety of the makers will have passed. Lastly, the project I think is the most interesting and takes place on the longest time scale is the Zeitpyramide (time pyramid) is a sculptural art project that will see 120 concrete blocks shaped in a pyramid completed over the course of almost 1200 years, with only one new block being added every 10 years. Starting in 1993 and as of 2023, there are only 4 blocks in the structure, and with the current schedule the project will be complete in the year 3183. If you include evolution as a creative act, then we're talking about a time frame of tens of millions of years, or including the natural beauties of the world like the grand canyon, then billions of years of rock and magma and water crushing and grinding together. Beautiful spiral galaxies on the edges of the known universe even longer.
All of this is to say that our perceptions of time and unveiling of the unknown can often be disappointing, and our expectations should be kept in check. The pitch drop experiment will keep dropping, John Malkovich's movie was sponsored by a cognac brand that ages it's product for 100 years, we already have visualizations of the time pyramids completion in the form of diagrams and pitch concepts, and evolution and star formation act on such a long scale of time that they may as well be static to us (as some actually believe). In the case of AI and "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made", it's important to keep our wits about and not let the hype/hate get to us. The promise of "The Single Greatest Piece of Art That Has Ever, Can Ever, or Will Ever be Made", and AI's benefits and consequences, are manipulated through time and language. Big words and high fidelity tech demo's only show a piece of the picture, just as in this project, the AI denoising of a timeless incontestable "masterpiece" slowly shows progress over time, but the final outcome is often disappointing compared to the buildup of hype we can be trapped in.
As it stands right now, I have this ComfyUI setup that I can naturally extend the steps on to an extent, which pushes the generation of an image from a couple seconds to a couple minutes. If I actually wanted to keep the AI going for longer than a day, my computer and GPU would probably burst into flames, so I need to think about ways I can work around this limitation to achieve the intended effect, and to introduce more design elements that can push the concept or prolonged process and the manipulation of time and hype more.
I think it would be a bit of a disservice to the concept if I knew at all what the AI would generate over a conceptual 100 years, but in setting up the system and getting a prompt going, I had to generate at least a couple images. With a massive prompt along the lines of "create a maximally creative piece of art that has no equivalent using any medium", the first image it generated I thought had a bit of poetic irony to it, although to be fair I made all the meaning myself.
Interesting that the seemingly maximally creative singular best piece of art ever created by an AI would be of a dark cube-like shape... a black box if you would, burst open to reveal the visage of a human head. As with all great art I'll leave it up to audience interpretation, since again with the AI image itself there is no inherent meaning other than what we make of it.
I think the concept is potentially strong as it is, but I think selling the execution as a Thesis project leaves maybe some more to be desired. I think if I can frame it correctly as an installation piece, as another interaction through time, this particular one focused through the lens of the hype/hate cycle, it could work a bit better.
Where the Next Steps are Leading
Evidently reading has been sidelined this week to crunch on these projects, which I will make a strong push to flesh out as much as possible both before the semester ends and before my committee meeting. These projects and making more progress on them aside, I have the Muse 2 brainwave scanner now that I have to build up a project on. The scanner is a little finicky and not the most consistent, so I will have to build accordingly to make it the most usable given its limitations. Combining it with more reliable face tracking and the emotive-reactive project makes more sense this way, as that can more drive the "dynamicism" of the project for a user to interact with, while the brainwave scanner can be more of something that activates the project from an idle state, as opposed to relying heavily on the brainwave data it produces. With as much progress as I've made on the installations, I've also had the chance to conduct 3 interviews with AI practitioners to get some insight on their outcomes in understanding AI, which I will have to lay out and decode some common themes on, and maybe reach out to more practitioners in the coming weeks, since the interviews are low-intensity I would be able to conduct much more depending on if I get responses from those I reach out to. Lastly, the workshop planning will take more precedent as I push forward with these projects and likely be a goal of mine through winter break to finalize.
This week I made more progress on the Non-Sentences project, and made more steps in the other two projects for my thesis: The Emergent Garden Interactive Edition and the Cognition project using the muse 2 brainwave scanner.
First for Non-Sentences, I've made more steps in solidifying the visual aesthetic of it, as it "vibes" towards an old computer monitor with a front end "terminal" on the right, and the network of words on the left. I added some feedback and gamma edits to make it more "glowy", and I'll explore some more effects like scanlines, some warping, and grain to pull it all together.
Another edition of this project to place it better in the installation space that Alex brought up which I think can tie it together is the addition of a receipt printer, to print each sentence and network physically. That would primarily take the form of a mono black and white version of the current setup landscape on the printer, and in physical space this achieves a couple of different things.
1) It will add a tactile layer of interactivity with audiences able to see physically what manifests out of a non-sentence, and adds a bit of small permanence to the sentences themselves, as they fade out of existence on the monitor, they would be preserved in their printed forms.
2) It serves as a physical representation of the scale of the "slop" the AI produces. While people would be free to take a piece of receipt with them as they please, I foresee many choosing not to, or no one being around to take them if the system runs autonomously, which would result in a pileup of the papers on the ground. This physical representation would show the speed of potential non-sense that is filling up the digital realm, translated into the physical, as well as an image of the environmental consequences of this non-sensical generation. As far as the content in the paper, as the system runs and runs the words would eventually start to homogenize, which is a potential concern as the internet is being filled more with AI content. AI is trained on human content, but as more AI generations fill the internet in writing and images, a potential feedback loop can occur where AI endlessly echoes and repeats itself based on what its already generated.
3) In the same spirit as number 1, the permanence also leads to the potential for something else to be created, as I can see a potential poster that lays out the receipts as something even longer lasting, and touches on calls for sustainability in AI. Turning nonsense into sense, and meaningless into meaning.
For the Emergent Garden interactive edition, I've taken steps to add this level of interactivity from my previously made TouchDesigner network. From what I've already done, I would say the project is at 1/3 done. The outputs of blob tracking, prompting, and visual code already exist in the project file, the next steps are to add the gestural interactivity of cultivating the garden with users hands: drawing shapes with their fingers and hands, and the physical hardware interactions of changing prompt parameters and the AI behavior with a midi pad. This dual interaction takes into account the hands that shape and the tools that build. The hands that shape the world around us as forming the backbone of the garden with the original primitives that can be physically placed and manipulated, drawn and erased, planted and uprooted. The tools that build, through the hardware and software, show the calculable effects the introduction of these tools can have on the garden, ecosystem, and world around us; but are ultimately driven by human intention and intervention. These interactions are the other 2/3 of the project that need to be done, but will take a primary focus in the coming weeks. As far as the physical space, I'll have the monitor setup with the interactions showing live the final evolving output, with the 3 printed posters next to it to both fill up the space of the exhibition and again to add some permanence to the outputs.
Finally, for the Cognitive Control project, I just got my Muse 2 brainwave monitor in the mail, so I'm excited to explore that and combine it with the face tracking - emotional control project I already have. I think what I'll want to touch on this one is the element of the known and unknown, how, since AI is such a new thing, it is not fully understood how it can affect our brain, but there is some research supporting it's affects on cognition, thinking, etc., both positively and negatively. For a visual I'd like to supplant some real images of brain scans in conjunction with a users real brainwaves, their face tracking, and the AI visual that ultimately comes out of it, drawing from highlighted neurons to create a pseudo-data visualization / visual commentary.
What I’ve Read
Reading this week focused more on play, interaction, and experience as they relate as defining terms for what I'm working on as a whole body of work: installations and workshops. The more I read into the following research papers and into Homo Ludens, it seems that play is naturally making it's way out of my thesis in favor of the cross section of interaction and experience, while some of the ideas of how I personally (and informally) would define play remain, but are more focused and intentional under these terms.
Starting with interaction, as I read more into it, it seems that it shares some similarities with play as a concept in being somewhat unambiguously defined in research, which is surprising to me with it's inclusion in the name of the field of HCI. There are just as many "towards a definition of interaction", "defining interaction", "in support of a definition of interaction" research papers as there are that substitute interaction with play. Some older but relevant papers: “Towards a Definition of the Term and Concept of Interaction” (Schwaber) and “In Support of a Functional Definition of Interaction” (Wagner) make more functional, operational, and rigid definitions of interaction.
Wagner grounds the concept in instructional and learning theory, defining basic interaction in learning contexts as "reciprocal events that require at least two objects and two actions", while also making distinct interactivity and interaction, with interaction as a learning-oriented process of this reciprocal influence between learner and environment, and interactivity as a technological affordance that enables such exchange.
Schwaber moves towards a more psychological approach to defining it, moving a little away from a strict learning environment, with interaction as an "intersubjective co-creation and reflection", again bringing up these ideas of reciprocal engagement between two or more parties but in a less rigid and pedagogical lens. Her definition emphasizes the co-creation of meaning through mutual influence and recognition between entities, in my thesis case this would be between a person and an AI: either through direct making in the case of the workshop, or through experience with the installations.
These definitions are well and good, but a bit old, and not directly related to technology or HCI, which is where Hornbæk & Oulasvirta's "What is Interaction?" fits in nicely, and makes up what these older definitions lack in their "folk notions". A direct HCI paper, they position interaction as "conceptual diversity and human-computer coupling", proposing not one but 7 different sub-definitions under the umbrella of interaction. These sub-definitions being:
Dialogue (turn-taking communication) Transmission (information exchange) Tool use (human action mediated through artifacts) Optimal behavior (adaptive goal pursuit within constraints) Embodiment (being and acting within a socio-material context) Experience (emotional and experiential flow) Control (continuous feedback systems minimizing error)
All of these relate in one way or another to aspects I'm covering in the workshop, or at least one / all of the installations, especially in experience, dialogue, tool use, and embodiment. I want to take note especially of experience and dive into it's own definition as well as it relates to my thesis, with one of my main source papers that I brought up in my midterm presentation that takes a look at experience as it relates to explaining AI, this being aptly named "Experiential AI: Between Arts & Explainable AI".
An overall definition of "experiential AI" in this paper is “An approach to the design, use, and evaluation of AI in cultural or other real-world settings that foregrounds human experience and context. It combines arts and engineering to support rich and intuitive modes of model interpretation and interaction, making AI tangible and explicit.” In other words, experiential AI makes the invisible operations of AI visible through human-centered experience by blending artistic methods with technical insight so people can feel, see, and manipulate how AI systems work.
The definition of experience in this paper is twofold. One is derived from experiential learning theory (Kolb, 2014), where experience becomes a medium for knowledge creation, as people learn through active involvement, reflection, and feedback (seen in what my workshop is trying to achieve).
The second definition is experience as aesthetic encounter (seen in my installations). This puts experience as directly graspable engagement, where audiences emotionally and cognitively interact with AI systems and artworks. These experiences foster understanding, critical reflection, and emotional connection.
Taking all of this together, I've gotten a working synthesized definition of the concepts as it relates to my thesis:
Interaction and experience are understood through the lens of experiential AI, where understanding AI arises through embodied engagement, creative co-creation, and affective reflection. Experience is both process and outcome, a space where literacy is gained through exploration, experimentation, and encounter. Experiential methods make AI systems legible, tangible, and emotionally resonant, transforming technical clarity into situated learning. Interaction functions as the medium through which this learning unfolds, a feedback loop that connects human curiosity, aesthetic interpretation, and algorithmic behavior, ultimately fostering technical and critical AI literacy.
This is by all means a working definition, and is something I will likely bring up in my committee meeting, since the workshop and installation projects will be happening regardless, this remains one insecurity in shaping and defining the overall theme of them together.
Where the Next Steps are Leading
Next steps are to continue the installation works, now that I have the Muse 2 I can work on that project more instead of sketching it out, which I'll start with the basic interaction and build it up from there (as seen in the process diagram I've continued to bring up). I'll need to reach out to see if I can get the space in the college of design by next week for sure, and I'll need to ask Carly in how to do that. Then I'll have to round out my presentation for the committee meeting, and gather any lingering questions or insecurities for the thesis itself.
Sources
Hemment, D., Murray-Rust, D. S., Belle, V., Aylett, R. S., Vidmar, M., & Broz, F. (2024). Experiential AI: Between arts and explainable AI. Leonardo, 57(3), 298–306.
Hornbæk, K., & Oulasvirta, A. (2017). What is interaction? Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, 5040–5052.
Kolb, D. A. (2014). Experiential learning: Experience as the source of learning and development (2nd ed.). FT Press.
Schwaber, E. A. (1995). Towards a definition of the term and concept of interaction. The International Journal of Psycho-Analysis, 76(3), 557–566.
Tawfik, A. A., Gatewood, J., Gish-Lieberman, J. J., & Kinzie, M. B. (2021). Toward a definition of learning experience design. Educational Technology Research and Development, 69(6), 2941–2962.
Wagner, E. D. (1994). In support of a functional definition of interaction. The American Journal of Distance Education, 8(2), 6–29.
//about
Ryan Schlesinger is a multidisciplinary designer, artist, and researcher.
His skills and experience include, but are not limited to: graphic design, human-computer interaction, creative direction, motion design, videography, video-jockeying, UI/UX, branding, and marketing, DJ-ing and sound design.
This blog serves as a means of documenting his master’s thesis to the world. The thesis is an exploration of AI tools in the space of live performance and installation settings.