This week was primarily focused on my thesis video project. At the time of writing it's not entirely done, I'd say around 80%, but there's enough structure and content for me to reflect and give myself some feedback before presenting them on Monday.
My video took the form of a video essay / motion graphic explainer, which talks about the sort of technical aspects of AI, and the conceptual side of the actual point of using AI to generate images. My inspirations for this are primarily from video essays on Youtube, with the best one's having rather high production, storytelling, and educational value (such as Vsauce, SEA, and Lemino to name a few). I chose this form to give myself the most breathing room in being able to explain these things through narration and through designed graphics. Motion Graphics to condense complex concepts into digestible information, and narration to fill in the gaps and breathe more information that the graphics alone might not cover. The final video will probably be around 5 - 5 1/2 minutes, which I think might be running a little long for the scope of the assignment and the time it's taking me to complete it, but there is a lot to cover, which I think will be beneficial as far as the actual written component of the thesis - getting the words out. In this instance it's in the form of a script, but that's much easier to convert to the written portion rather than keeping it all in my head (the written portion will be beginning to be drafted in the next month as per my timeline).
I also think the use of motion graphics is beneficial to me for a number of reasons. They're more engaging than static images or posters (such as the emergent garden poster, which will be referenced in the video), they're interesting and fun for me to make and in putting them to practice I am inherently learning more, they provide a basis for a possible branded component of the thesis (valuable in a portfolio project) and they are a valuable skill to have in practice (and can make you more $$$).
Additionally, motion graphics are an area in design which AI hasn't quite breached into yet (successfully at least), as there is a lot more nuance in designing something graphical that's moving and consistent at 60fps, with a plethora of effects and design choices to make along the way. Of course, you can input motion graphics as a starting point for AI to compose over the graphics you make, but from a start-to-end process it still has a long way to go in this area.
Some highlights from the video are below in .gif format:
These might not display correctly as intended as .gifs on WordPress, they're making my browser lag as they're being uploaded and the frame rate is drastically reduced from what they're meant to be at, but I am happy with how they are looking in the final video. I used a mix of After Effects and Cavalry to make them.
In doing this assignment I'm thinking on the value of what a motion graphics piece could look like for my thesis, and thinking that it could be something that could be incorporated, even if I'm not actually using AI. I'm thinking about Mira Jung's thesis, where she used interactive motion graphics with sensors that played when people crossed a certain threshold of a projector setup, and how something of a similar nature might be used in mine. Additionally, while I think the video may be a bit on the longer side for this assignment, I think what Alex said in class on having a "directors cut", or more specifically, a longer form of the video could also be beneficial for my thesis. Something that's lacking in the video as it is now is a more in-depth overview of how AI works, because there's a lot more to it than what I could cover, such as datasets, how a model is trained/learns, or even on their history, covering things like Joseph Weizenbaum's ELIZA the first AI chatbot, or Harold Cohen's AARON, the first AI painter. I also couldn't cover some of the ethical concerns about AI, which, although my thesis isn't primarily focused on these ethical aspects, it's hard to not talk about AI without covering them at least briefly.
What I Read
Reading again took a little backseat this week so I could focus more on the video project, so I mainly continued reading Transcending Imagination for a couple chapters when/where I could.
In Chapter 3, Form Shapes Perceptions, Manu emphasizes that form is more than structure: it's the framework that shapes how we see and interpret reality. AI and virtual reality accelerate rapid iterations, allowing artists and designers to experiment and create new realities at unprecedented speed. Personally, I think this is a played out view on AI and can undermine its value a little bit. It harkens back to the age old quality vs. quantity tension, where now more than ever people can produce visually interesting things, but the quality might not be there, as evidenced by the AI "slop" that permeates through social media nowadays. However, there is value in this democratization of image making, which I relate to in my "Image Space" section in my video, that of which playing with AI in rapidly making images can let you throw lot's of ideas at the wall to see what sticks so you can run with it further. In this sense AI can act as a sort of filter of ideas, and an unexpected idea maker, which he expands on in Chapter 4
Chapter 4, Incidental Beauty, explores beauty as something that often emerges unexpectedly rather than being deliberately designed. While art and design can intentionally align intention and perception to produce beauty, incidental beauty arises from chance encounters like "a spider’s web in the dew or graffiti illuminated by sunset—that surprise and provoke wonder." This is the art of noticing, and these moments of unplanned beauty challenge fixed aesthetic beliefs and encourage mindfulness, urging us to see the world with fresh eyes. Manu argues that AI-generated art also creates opportunities for incidental beauty by producing unanticipated results, expanding aesthetic diversity and reminding us to remain open to surprise and transformation in our experience of art and the world. I bring up this concept in my video too and I think it relates great to play, as exploring with AI in low stakes and fun environments can lead to something greater.
Where the Next Steps are Leading
Immediately there are a couple things I need to finish with this video, and I did see your (Alex's) email with the IRB form that I need to fill out, which inevitably leads me to having to hone in a little more on the aspects of the interviews and workshops that I need to conduct, things like the audience I'm working towards and the questions I need to ask. After this, into October and November, is deliverable crunch time, where I fill focus on more project based stuff, like a longer form video or TouchDesigner projects. Additionally on the research side of things I want to focus on drafting solid interview questions first after IRB.
This week I focused on creating my submission for the AI poster competition at Iowa State. The poster I made is titled "The Emergent Garden", and speculates on a garden the shows the real-time evolution of fauna, and is inspired by some of the readings I've done that draw parallels to AI and biological evolution. I think this was valuable for my thesis in order to actually document an AI workflow process that involves creativity and play, as the submission required for a "diagrammatic" process explanation with charts, flows, etc. Additionally, in crafting the artist statement, it got me thinking about additional ideas my thesis could go inside the real of play, creativity, and AI, specifically as it regards to human connection, with each other, with technology, and with our shared ecosystem as a whole. The poster and artist statement are below.
Artist Statement:
The Emergent Garden is an AI data-driven poster that imagines creativity as a living, evolving ecosystem. Inspired by parallels between artificial intelligence and biological evolution, it explores how new forms can emerge without conscious intent yet still hold deep meaning for us as humans.
Creativity is often seen as uniquely human, tied to intentionality, consciousness, or free will. Yet one of the most creative processes in nature, biological evolution, has none of these traits. Natural selection shows that beauty and novelty can arise without intention. Similarly, AI generates infinite variations, not to “survive,” but to spark reflection in those who encounter its outputs.
The Emergent Garden speculates a space of care and curiosity. AI’s constant retooling and reprompting reveal an evolution of images in real time. The poster envisions a garden that algorithmically grows unique fauna, never quite the same, offering a shared experience that reminds us of our role as co-creators and caretakers of technologies, ecosystems, and each other.
By blending organic and artificial, the garden suggests creativity is not only invention but also tending to connections: between human and nonhuman, natural and digital, self and community.
At the time of writing this post I haven't quite finished charting out the process, but it involved using edge detection data of the AI generated flowers to blob track and connect points across the canvas, and followed a similar path to the process chart I demonstrated way back in the initial presentation, using pre-processing primitives to "draw" the shape of the flowers before the AI enhanced them, weighting it accordingly to get the desired look, feel, and "vibe" that I wanted, then post-processing in Photoshop to add the more static text elements, such as overlaying the blob tracking script, which touches on the transparency and tech literacy I am looking towards in my overall thesis.
What I’ve Read
Reading took a little bit of a backseat this week, but a book I've discovered called "Transcending Imagination" is very interesting, and touches on how creativity has and will change in the AI era. The author argues that all art is inherently artificial, shaped by human intention, and that AI complicates traditional boundaries between the “natural” and “artificial.” AI, he suggests, should not be feared but embraced as a collaborator that expands human imagination rather than diminishes it. Creativity is reframed through the cycle of intention, articulation, and manifestation, with AI extending human intent into forms that often exceed what creators can imagine. By moving beyond reliance on archetypes, such as familiar design patterns like chairs or cars, AI allows artists and designers to explore radically new possibilities. Rather than threatening creativity, it introduces unpredictability and beauty that challenges our perception and deepens our understanding of art’s purpose.
This can be related to play as a means of expanding our horizons with AI and creativity. With play, I feel like breaking away from structured "reality" and archetypes allows for more imaginative creations, which can then be reintroduced to these archetypes, opening the door to more unseen possibilities than without play, or the play with AI. This is only from the first chapter, and I'm excited to read more on it.
Where the Next Steps are Heading
Aside from the immediate next steps, like continuing to read "Transcending Imagination" and finalizing the process diagrams for the poster submission, my main next steps are more formalizing the workshop and interview processes. I submitted my IRB earlier this week, so pending that I can continue in defining how those look and how they fit into my thesis, such as honing in on an audience like we talked about in class on Wednesday. Additionally, we have the video project coming up, which I think will take the form of an explainer-video essay style video consisting of motion graphics to break down some of the bigger AI concepts into digestible information (on the topic of transparency and AI literacy). I think there is a way to tie in the Emergent Garden piece into it as well, since being made in Touch Designer, it allows for a motion aspect to be further explored as opposed to a static poster, which can highlight the real-time evolution that the poster speculates on.
Bibliography
Manu, A. (2024). Transcending imagination: Artificial intelligence and the future of creativity. CRC Press.
This week I did a bunch of reading and writing down notes during our work days in class. Outside of class, I did some experimenting with the AI Agents that can read and write on my computer in an attempt to make as autonomous as possible creative works, which had limited and mixed results, but could be something to explore in different ways in the future.
What I made
One solid accomplishment I made this week was getting my academic plan approved. Maybe accomplishment is the wrong word, since it's as simple as listing all the classes I have taken, and the 3 classes I will take next semester. But still, it's a thing crossed off the list and one less thing to have on my mind over the coming months.
Now as far as something tangible, I managed to get those AI agents working in some capacity on my computer to output some simple art files, which was an interesting process. It was simple to get the API keys for Claude's Sonnet 4 model and get it to simply run a "hello world" -esque test, but achieving autonomous artistic creativity was a much more challenging prospect, which was to be expected given the current state of AI. However, getting mostly "un-prompted" images was achievable as far as getting the AI to make image files of it's own design. I still did have to prompt it, which is an inherent aspect of AI currently, but in wording it out I aspired to give it as much agency as possible to iterate upon it's own work for as long as I could run it.
The prompt:
"You are an artist agent. Be maximally creative, clever, and unique. Create and evolve generative artwork with python scripts. Write 2 python scripts that each create a file called art1.png and art2.png, then run the scripts, then 'look' at both image files. choose your favorite of the two, then create successor artworks that overwrites the previous python scripts with variations/improvments on the previous. Also, create a helper script that runs both python scripts, produces the art files, then combines them into a single art.png file that stacks both images on top of each other so I can see both. This combined art file should be the one you use to read and select a favorite. Repeat this behavior endlessly: create, observe, select, modify, over and over. Do each with separate agentic actions, do not just write one script that runs forever. Do not stop ever or ask for approval. The generated images should be high resolution, 1024x1024, and be as unique, creative, and beautiful as possible."
The hope in getting it to run python scripts to create the images and then compare them was to allow it to run in a lightweight repeatable environment that it could look back on easily, since it's not actually 'looking', just analyzing the image contents and it's own scripts. Of its own accord it installed the mathplotlib python library to write and render equations that could be seen as "artistic". It was only able to do so much though, and got through 2-3 images per run before getting stuck. The images it made in a limited time frame are below:
Unfortunately, it was getting stuck in the sort of self-iteration and evolution I was hoping for, but I think even in these abstract images there is something to say about how the model is defining it's own artistry through scripts of it's own design. Something I read about in class was this concept of image space. Constrained to a 1024 x 1024 RGB pixel space, where each pixel can have a different combination of 256 values for red, green, and blue, the total possible unique images under this format is 16,581,3751,048,576, a number with over 7.5 million digits. For comparison, the number of atoms in the observable universe is 1080.
This is an unfathomable number, but it's scale becomes somewhat trivial when a vast majority of the images in image space are just random noise. The Universal Slide Show from The Library of Babel showcases this concept, where 'unique' images are constantly being cycled through, but each and every one of them looks like this:
So there's obviously a difference when looking at this random noise vs. the images the AI model created. The colors and forms are arranged in a way to make the notion of spirals, depth, and layers. This makes me ask: in all of image space is there a subset number of "creative" or "valuable" images that distinct themselves from this noise? This is for all intents and purposes, probably unanswerable, but then this leads to the question of if it takes a human to define this value? The AI could have certainly spit out some random noise and called it art, but on the surface there seems to be some mutual understanding in charting image space for aesthetically distinct images from noise.
What I read
During class time I read a lot on some of the research-oriented processes that will back my thesis, these two areas are practitioner interviews (1-1 interviews with artists in the field currently using AI) and a workshop diving into the creative process with AI (using pre- and post-surveys to gain qualitative and quantitative insight into how the process resonates with those using it).
Starting with interviews, common themes and questions among them were diving into interviewees processes, looking into positive aspects in their uses of AI (finding enhancing, enabling, opportunistic, or controllable elements within their work), the negative aspects of the use of AI (inhibiting, constraining, hindering, limitations within their work), ethical considerations (risks, critical reviews), and future forward questioning (changes in fields, improvements and introductions, evolution). These lines of questioning are important to ask both artists using AI and artists not using AI to get a comprehensive view of the current landscape, and answer some of the Big W's + H questions: What are people doing with AI creatively, who is doing it, when are they introducing it in their process, how are they implementing it, and what effects does it have on their process and the perception of their work? These are great questions to ask not only others but myself as I go further down the funnel. Two studies in particular that stood out to me were EXPLORING HUMAN-AI COLLABORATION IN THE CREATIVE PROCESS: ENHANCEMENTS AND LIMITATIONS and EFFECTS OF IMPLEMENTING AI IN PRODUCT DEVELOPMENT, FOCUSING ON INDIVIDUAL CREATIVE PRACTICES.
On the side of workshops, there's surprisingly little that focus on the actual deliverable of AI artifacts, but most of them focus on the exploration of AI in a collaborative sense to augment an individuals creativity. In contrast to the workshop I ran with design social, there seems to be a lack of "fun" or "play" in these AI workshops when it comes to things like image and video generation, or even mixed forms of interactions like I'd done with hand or face tracking. Maybe this is a gap in research: using AI for fun instead of a pure productivity enhancer? The product development paper I read above did a qualitative experiment as opposed to a workshop, in which the results touched on the side of human agency and authorship, emotional connection such as motivation and engagement, and perceptions of trade-offs and gains in AI-supported work. These are interesting talking points, in which I'm thinking could be explored more or differently in a workshop setting as opposed to a qualitative experiment. This also relates to another workshop proposal I read on AI in a creative process, in which the 3 sections were Serendipity, Collaboration, and Creative Reflection: using the randomness of AI (serendipity) to drive the collaboration of a creative artifact, then coming back together and reflecting on the process.
Where the Next Steps are Leading
From the readings, research and mini-experiments so far, I feel like I'm getting closer and closer to having a concrete question(s) to ask that can drive the rest of the thesis. What questions can I seek to answer through research, interviews / workshops, and the prototypes / projects I make? Some ideas so far, but certainly not limited to are: What is the role of AI in low stakes creative fun/play? What new definitions does AI take in this space? (Genre/Material as opposed to Collaborator/Tool). How does the idea of image space come into play? Can AI be autonomously creative? What's limiting it in doing so? How is creativity defined? (Creativity = New + Value?, How do we define things that are new or valuable? Can AI really be New-New?) This will be a crucial step in my thesis, one I'm excited to take.
As far as projects, I would like to continue refining the agents that are "charting image space", and see if I can make them run on loop for longer than 2-4 images before getting stuck. I also have another project idea that involves using a Muse2 brainwave monitor on a person to drive AI image generation, which airs on the side of speculation of future collaboration. To that idea I would start by sketching it out first, but before I pursue that avenue the research question would come first.
Bibliography
Martinsson, T., & Svedberg, M. (2025). Effects of implementing AI in product development, focusing on individual creative processes (Master’s thesis, Uppsala University). Uppsala University.
Yamada‐Rice, D., & Mordan, R. (2022, June). Augmenting personal creativity with artificial intelligence [Conference workshop paper]. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. ACM.
Patama, S. (2025). Exploring human-AI collaboration in the creative process: Enhancements and limitations (Master’s thesis, University of Jyväskylä). University of Jyväskylä.
This week being the first progress report, I'll mainly cover my presentation content, what I learned from it, and how I can move forward in the best way. I'll also cover some readings I covered this week in other classes that can relate to my thesis in one way or another.
What I’ve Made
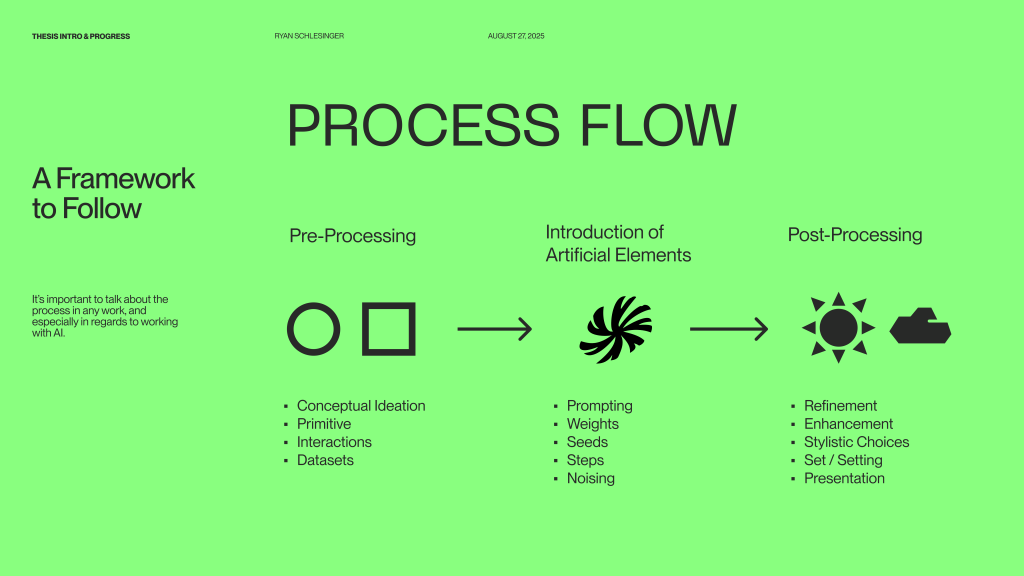
Reflecting on the presentation and how it went, I wouldn't say it went the best, or was really up to my personal standards. I've certainly done better presentations in the past, but it was valuable in understanding where I'm at in regards to the development of my thesis. In taking a couple days to organize my thoughts, it is apparent that I need to narrow down much more the topic and I what I am really trying to accomplish, which is why I feel I was so disorganized in communicating my thoughts. I certainly have ideas for interesting projects that incorporate AI in non-traditional ways that change the mode of interaction, but putting them all together in a meaningful way is certainly a necessity and a lacking part of where I am currently at. This was reflected in the feedback from the audience as well, with good considerations and questions for me to think about on how to make the body of work more accessible and understandable for a broader audience.
There were some good things, however. The process framework is a valuable asset to have in the time to come for the development of some of the bigger ideas I need to have. Putting a process down like this is a good way to organize thoughts on a project level, and a source of organization/deliberation to come back to as things progress. As with most other aspects of my thesis at this point it will need refinement in its presentation and applicability. It is also a source of accessibility too. If I were to conduct a workshop that goes through a creative workflow with AI, even a high-level process like this could open new ideas and avenues for exploration from participants.
Lastly, even if conceptually I still have a lot to work towards, the project ideas I mentioned do exist and remain an actionable component I can work on. For example, something I can immediately work on from the presentation I briefly talked about is this system I made in Touch Designer that pulls from Wikipedia's API in order to visualize in some way the insurmountable data that AI models pull from all corners of the internet. My initial idea to expand on it is to create a database of words separated by their type of speech / sentence structure (i.e. separated by noun, verbs, adjectives, etc.), then have a text to speech model randomly ping out words in a common sentence structure. The goal in something like this is to visualize the process of an AI deliberating on how to come up with a sentence in a typical chat interface, and how this can lead to hallucinations or misinformation. The "sentences" it makes are structured right and contain the right words, but the context is absent and construed, and the meaning is obscured or non-existent from a human angle.
What I’ve Read
This week I've had the chance in some of my other classes to read on AI in a couple different areas, one paper in particular on how AI is changing the creative process with some examples or artists using it in unique and alternative ways, and criticism and pitfalls with including it in the creative process.
The article, titled “AI to Supercharge Creativity”, situates generative AI not as a replacement for human artistry but as a potential collaborator that reshapes how creativity unfolds. Featured artist Lizzie Wilson demonstrates this through live coding performances, where an AI “agent” injects unexpected loops and rhythms into improvised live-coded music, pushing her beyond habitual choices. Her approach touches on points of co-creativity I wish to cover in some facet in my theses, in which AI acts less as a producer of polished outputs and more as a partner that surprises, provokes, and challenges human thinking. These interactions shift the focus of creativity away from automation and toward augmentation, and a dialogue between human intention and machine suggestion.
Those interviewed in the article emphasize that creativity requires friction, reflection, and even failure. Mike Cook notes that removing failure from the process, as frictionless generative tools often do, undermines the very struggles that cultivate artistic growth. Similarly, Jeba Rezwana critiques the “one-shot” interaction of systems like Midjourney or DALL·E, which automate creation but limit back-and-forth iteration. This concern reframes AI not as a means of efficiency but as a medium that should slow us down, forcing reconsideration and experimentation. Elisa Giaccardi echoes this by asking whether true creativity can exist without material that “pushes back,” underscoring the importance of resistance and surprise in the creative process. In the case of Lizzie Wilsons live coding performances, the AI doesn't make the music for her, but introduces new rhythms that can be supplanted into her performance. "Sometimes it goes wrong, and that’s just part of the creative process." - Lizzie Wilson
Ultimately, what I gleamed from the article is that the future of AI in creative practice depends less on making outputs “better” and more on making processes richer. The tension between control and surprise remains unresolved: commercial tools offer accessibility but little agency, while research prototypes provide depth at the cost of usability. The most promising direction as far as creativity lies in viewing AI not merely as a tool but as a material. It's something to be misused, bent, and challenged, just as artists have always done with paint, clay, or sound. In the development of my thesis, this reveals an importance of designing AI systems that expose bias, embrace failure, and provoke reflection, reframing creativity with AI as a dialogue that reaffirms human agency, where the AI can have a helping hand in shaping the outcome, not the other way around.
Where the Next Steps are Leading
My next steps from this point based on the presentation and reading are again to further pursue the conceptual development of my thesis, really narrowing down what I want to say and how I can say it. As far as class activity, I think the flow chart we will be making can help in this pursuit, where to divy time between project based work and conception based work. I have projects such as the wikipedia api network that I will hope to achieve a more in-depth version in the next 1-2 weeks, but my main goal is to read many more research articles and past thesis' that can help in this organization and narrowing down of ideas. What has been said already, what can be said now? On the horizon in the next month would be to develop a workshop process that emphasizes accessibility using the process flow I've made, but the overall goal stands to reposition and narrow down the subject matter, keeping in mind accessibility and messaging, and how that can be supported by projects I've made, prototypes I will make, theories, and process documentation.
Bibliography
Heaven, W. D. (2025, May/June). AI to supercharge creativity. MIT Technology Review. https://www.technologyreview.com/
Hello un-prompted viewers, it's been a little while.
I plan to upload a little more frequently, especially as thesis things start ramping upwards and forwards, but I would like to share some projects and some technologies that I've discovered and worked on that are in this realm of AI, generative form, and interactivity.
I mentioned in a previous post that an aspect of my thesis would explore the interaction of generative audio and generative visuals. The projects and technologies in this post reflect that sentiment.
First on the technology side, I have been exploring the integrations of AI audio in a realistic way using OSC data that can be utilized in TouchDesigner for audio reactive visuals. At first I wanted to write some type of python script that could continuously generate audio which could be fed into TD, but technologically that is somewhat beyond me and involves a lot of setup in previous python environments that in the end I decided would take away from the final output. If I can achieve the result I want within a program, that works just as fine.
So for program explorations, two options come to mind: Ableton and VCV Rack. Both have the ability to make traditional generative music, particularly ambient sounds which was first envisioned and created by Brian Eno in the 1990's. Both also have AI integrative plugins for more extensive generative audio, and fit more into the idea of what AI is post 2023.
Of course there are pros and cons to each platform. Monetarily, Ableton is paid and VCV Rack is free (there is a paid version but to my knowledge right now most everything is achievable in the free version). The Ableton user interface is a bit more digestible and is inherently integrated with TouchDesigner through TDAbleton, compared to the VCV Rack interface (above), which takes inspiration from classic node-based audio synthesizers, and can get pretty chaotic. VCV Rack also does not have native integrations with TouchDesigner, but again through OSC data and specific plugins this is made easier.
I'll need to do more explorations, but at the end of the day I will choose which one can more effectively integrate newer AI audio generation with the traditional audio generation systems.
PROJECT CONCEPTS
Aside from more technological explorations, I have made some demo projects that integrate AI, Audio, and some motion/facial tracking.
The first of these projects is shown below and was made in TouchDesigner with the StreamDiffusion and MediaPipe plugins, and I refer to it as "Emotive-Reactive AI".
The project tracks the users face as shown by the 3D point map, and using the corners of the mouth for 'happiness' and the brow for 'sadness', the user controls the prompt weights for each side, showing calming and pleasant images when the user smiles, and bleak solemn images when the user furrows their brow. The prompt for each emotion is also randomly taken from a prompt list when the users emotion reaches a certain threshold, which accounts for the change of image. Finally the input media is taken from a solid facial model tracked from the users head, with a noise filter overlayed in order to fill the entire block.
Expanding on this I created a variation that incorporated pre-generated AI audio tracks for each emotion, that similarly increase in volume with the intensity of the users emotion. Changing from the landscape scenery from the first iteration, the AI takes primitive abstract shapes as an input, and meshes them together after passing it through the model.
Additionally, I explored more on the visual side with audio from some musicians I know, and creative some semi real-time audio reactive AI visuals, through straight audio inputs, and a system that can be manipulated with a midi controller, in my case the LaunchControl XL.
AI Audio Graffiti manipulated by midi controller.
AI audio reactive galactic visuals render.
These were great explorations for me to get started on actual deliverables for my thesis, and to see what's possible and what's not with the programs, plugins, and techniques chosen.
Building something from the ground up can be daunting, but a good foundation is essential in keeping it all together.
People learn different things in all sorts of different ways. Some by studying vigorously for long periods of time, others by getting their hands dirty and diving head first into the thick of it.
I think I fall more-so under the latter, but I think that different areas afford more learning opportunities from one or the other. Again, I think this is very true for coding and design. You can learn a lot from studying syntax and learning UI's, but you'll never get anywhere if you don't sit down and do something with what you learned.
As the blog and my thesis go on, I'll start posting weekly, but for now I'm in a fervor, wanting to add to this as much as I want to add to my expertise in the tools I am working with.
TouchDesigner peaked my interest as a creative tool way back in the pandemic days, and slowly but surely I've been building my knowledge base in the program. Thankfully, I've had more than personal projects to work on with it, so as far as practical use I can add a couple notches to the belt.
Something I'll likely end up doing for my thesis is creating a UI within the tool, and my contemporaries have done similar things, such as Bileam Tschepe's algorhythm tool, which essentially recreates Resolume within TD. However, the tools to create that within TouchDesigner I'm not wholly familiar with, so this was a nice experimentation into that realm.
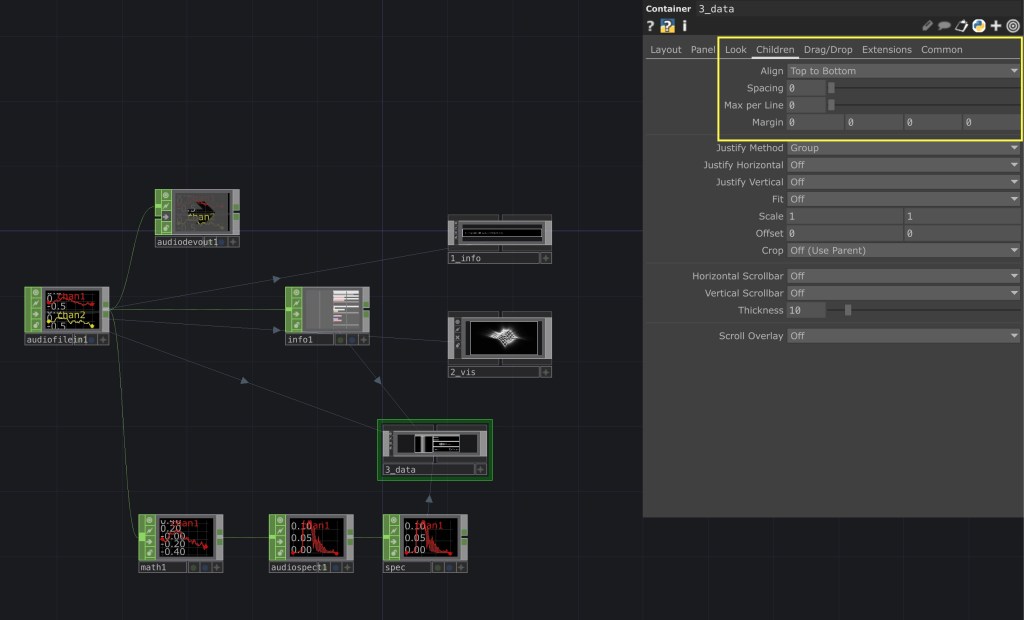
This visualizer is made up of 7 compositions in TouchDesigner, with each one having various levels of stacks to it.
For those who don't know, TouchDesigner has 4 main levels of node: TOPs (2D Visual), CHOPs (Data), SOPs (3D Visual), and DATs (Code and Text Editing). Combining these is nothing new to me, but the container interface is, which is from a sub-level COMP node.
Putting these together was surprisingly intuitive, with some preset options on how you want to display the visuals within one another.
As you can see in this screenshot, the composition has alignment options to evenly distribute the child containers within it. The hard part comes from making sure that the children containers have the correct dimensions, which can be easily done with some quick expressions.
I'll wrap up this post here as to not get extremely technical since this doesn't exactly relate to my thesis other than some extra practice. One last thing I'll showcase is the building blocks the interface is laid upon: just the audio file and a couple of CHOPs to get what we want out of the song data.
You can see on the right the containers that make up the visualizer, with the "3_data" container having 5 nested inside it. All the connecting lines show a reference of some sort to this original network.
Things are going to get complicated fast, but if this quick run through taught or reinforced anything to me, it was that the foundation is already there, it always was, its up to you how you want to put it together.
Sometimes the hardest part of a creative journey is the beginning.
Getting the pen to paper can be a daunting task, no matter what venture it is. Even with my thesis, the ideas have been swirling around for a long time, and of course doubt finds ways to creep in no matter what. "Is it a good idea?" "Does it meet any scholarly requirements?" "Could I even successfully execute something like this?"
The answer to all these questions is yes, and then eventually even more questions. Sometimes you don't even need an answer. There are of course many ways to help mitigate doubt in the creative process. Reading others experiences, writing down any thoughts good or bad, rubber-ducking with a mentor, or an actual rubber duck.
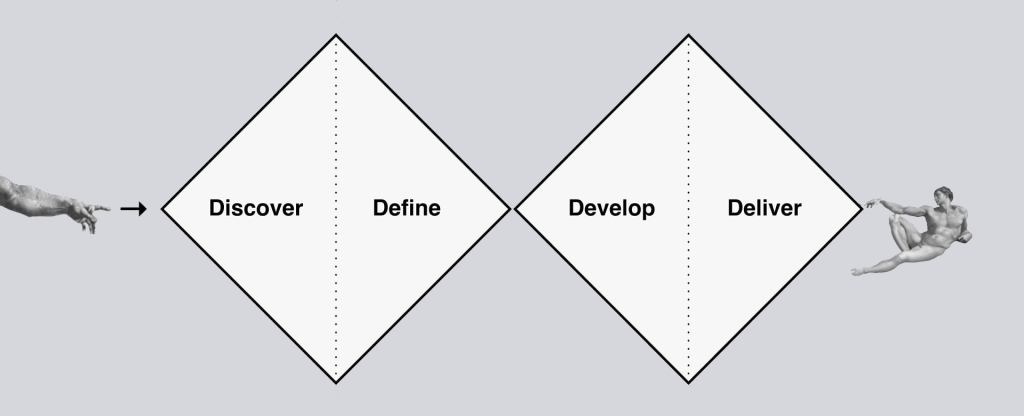
Personally, I like to temper my expectations, but leave room for wild ideas and practicing the dark arts. It's a fine line between a "go with the flow" and "shoot for the moon" mentality versus being realistic about personal ability, time management, and hardware/technological limitations. My mentor and major professor for my thesis introduced me to the double diamond methodology of practice. The funnel starts wide, exploring any possibilities, eventually closing in until you find a unifying point that brings it all together. Then the funnel opens up again, going from that point into more possibilities, until it closes yet again as a complete work.
In terms of actually starting my thesis, I've already done a couple things set-up wise before making this website. I started with downloading StreamDiffusion and TouchDiffusion, TouchDesigner widgets that integrate Stable Diffusion (I already have had TD for a while), AutoLume, an AI model research tool with live visual functionality, and Cables.GL, another node-based coding tool that functions similarly to TouchDesigner, but offers increased web functionality.
Of course, I have used TouchDesigner frequently in the past for performance and web visuals with and for some artists, you can find some examples of this work on my portfolio.
In terms of my thesis, I will be using these tools to explore the role these AI tools can have in live performance and installation settings, paying particular attention to different areas of interaction between a human and an AI model. As AI is still in its infancy, there may be even more tools that come up in the next year or two that can help or add to this project, which I am extremely excited to see what people make.
If you're reading this, I want to extend my thanks for taking the time to check in on my progress. Hopefully you'll stick around for what will come in the future!
-Ryan
//about
Ryan Schlesinger is a multidisciplinary designer, artist, and researcher.
His skills and experience include, but are not limited to: graphic design, human-computer interaction, creative direction, motion design, videography, video-jockeying, UI/UX, branding, and marketing, DJ-ing and sound design.
This blog serves as a means of documenting his master’s thesis to the world. The thesis is an exploration of AI tools in the space of live performance and installation settings.